


啥是FAQ问答系统?
摘要:FAQ(Frequently Asked Questions)问答系统是目前应用最广泛的问答系统。这种问答系统的结构框架明了、实现简单、容易理解,非常适合作为问答系统入门学习时的观察对象。这里基于本人在问答系统建设方面的“多年”经验,对FAQ问答相关的定义、系统结构、数据集建设、关键技术、应用等方面进行了整理和介绍。
1引言
2019年至今(2020年),我一直在做问答系统相关的NLP工做。这里使用一些同志的话术再说一遍:“小可已经深耕问答系统多年”。很惭愧,只做了一点微小的贡献——我负责、参与、观摩和听说了问答系统中若干模块的建设与应用。
在这些工作的初期,有几个问题困扰着我:
(1) 问答系统是什么?
(2) 问答系统有存在的意义吗?或者说,这玩意儿值钱吗?
(3) 问答系统怎么建设呢?
从技术,即实现方式的角度来看,问答系统有很多种,包括基于FAQ的问答、基于知识图谱的问答、基于文本的问答等等。这里围绕应用最为广泛的FAQ问答系统,对问答系统的定义、思想、基本结构、方法和应用价值进行介绍。
2什么是问答系统
2.1什么是问答
什么是问题,什么是答案呢?当我们某个事物的了解不够全面或深入的时候,就会感到自己缺少某些信息a,脑海中会下意识或主动地生成一段信息b、表达自己的困惑,如图2-1。我们称信息b为问题(Question)。如果有(他人提供的;天上飞来的;等等)一段信息c,恰好可以补上“缺少”的那些信息a、解决我们的困惑,如图2-2,那么这段信息c,就是问题的答案(Answer)。


在检索领域领域,我们把问答系统看做一个特殊的信息检索系统,并称问题(question)为查询语句(query)。
2.2什么是问答系统
一般情况下,当我们提到“问答”的时候,实际上指的是问答系统。“问答系统”的定义有广义和狭义两个层面。
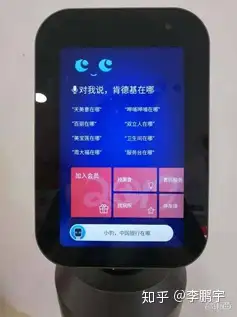
广义的问答系统指的是这样一种系统,它接收自然语言形式的查询语句,直接返回答案,如图2-3。常见的(实体或虚拟)问答机器人、客服机器人等,支持键盘输入或语音输入问题,也可以以图、文、音等形式与用户交互,软硬件结构齐全,都属于广义的问答系统。如图2-4,即我在
第1节中提到的那个机器人,可以解决类似“厕所在哪里”的信息需求。

狭义的问答系统,实际上是广义的问答系统中的软件系统,主要是知识库、检索模块、答案生成模块3部分。本文第3节将介绍的,是狭义的问答系统。
2.3问答系统与搜索引擎的区别
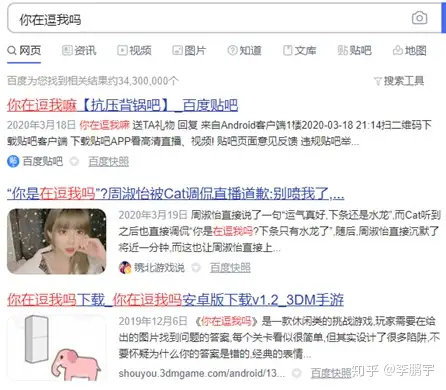
目前,我们主要的信息检索工具是搜索引擎。搜索引擎在接收到用户的查询语句之后,会从文档库中找到最有可能包含答案的若干文档,并返回给用户,如图2-5。由于这类系统返回的是一个文档列表,我们还需要精读文档、找到需要的信息。
问答系统试图做的更多。这类系统在接收到用户的问题后,会直接给出答案,而不是可能包含答案的文档列表。比如FAQ问答系统,它以(与用户问题同分布的)标准问题为桥梁,将用户与答案连接起来、允许用户直接获得自己需要的信息。
理论上,相比搜索引擎,问答系统可以大大降低用户在信息检索活动中的时间消耗。
3 FAQ问答系统的基本结构
3.1总体结构
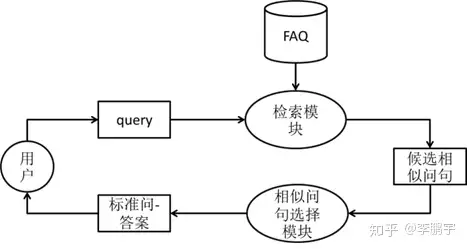
如图3-1,是基于FAQ的问答系统总体结构。系统的关键模块包括:(1)频繁问答对数据集,即FAQ;(2)检索模块,负责从FAQ中检索可能与用户query相似的若干标准问句;(3)相似问句选择模块,负责从候选相似问句中,选择与用户query最相似的标准问。
系统的工作过程是:
(1)检索模块会在理解query的基础上,从FAQ数据集中检索K个与query最相似的问句。这K个问句,被称为候选相似问句。
(2)相似问句选择模块从K的候选相似问句中,选出于query相似度最高的那一个,并判断是否具有足够的置信度。如果相似度最高的候选相似问句拥有有足够高的置信度,相似问句选择模块会判定该问句就是query的同义问句、它的答案就是query的答案。此时,系统会把这个问答对返回给用户、作为回答。
3.2主要模块简介
用户指使用问答系统的人或机器。问答系统可直接向人类提供答案,也可以向需要问答能力的其他系统提供答案——对问答系统来说,二者的行为是相同的,一般都以api调用的形式进行,因此我们统称二者为用户。
用户会向系统提出问题,即查询语句、query。
FAQ,即Frequently Asked Questions、常见问题,是业务场景中用户最常问、或最有可能问的问题,又称“标准问题”。对这类问题,我们可以提前编制答案,构成问答对。问答对通常简称“QA对”(Question Answer Pair)。问答系统的知识库中存储的FAQ数据集,实际上是标准问及其答案构成的QA对数据集。
相似问句选择模块的任务,是从K的候选相似问句中,选出于query相似度最高的那一个,并判断是否具有足够的置信度。如果相似度最高的候选相似问句拥有有足够高的置信度,相似问句选择模块会判定该问句就是query的同义问句、它的答案就是query的答案。此时,系统会把这个问答对返回给用户、作为回答。
4 FAQ问答系统的核心——频繁问答对数据集
4.1 频繁问答对数据集是什么
FAQ,即Frequently Asked Questions、常见问题,是业务场景中用户最常问、或最有可能问的问题,又称“标准问题”。对这类问题,我们可以提前编制答案,构成问答对。问答对通常简称“QA对”(Question Answer Pair)。问答系统的知识库中存储的FAQ数据集,实际上是标准问及其答案构成的QA对数据集。
我们可以把FAQ问答系统看做一种基于知识库的QA系统。这种系统的知识库,就是频繁问答对数据集。假设我计划开发一个问答系统,用于辅助游客了解西北重镇神木,那么我需要建设一份问答对数据集,用来存储关于神木的知识,如表4-1。
表4-1 一个频繁问答对数据集
序号问句答案1神木在哪里?神木坐落在陕西的北部。2神木有啥可看的?很多,比如二郎山、九龙山、神湖等。3现在去神木需要检查健康码吗?不需要。4兰州在哪里?兰州在甘肃省。5圪柳咀村在哪里在神木贺川。………问题来了:频繁问答对数据集有什么用呢?
4.2一个知识点有多少种问法?
表4-1中第一个答案,是一个知识点。指向这个知识点的问句只有一个吗?答案和孔乙己世纪之问的一样:不止一个。我们还可以问“神木在什么位置”“神木在陕西的哪个位置”等等。这些问句的含义基本一致,被称为“相似问句”。换个方向,我们说,相似问句的答案是相同的。这是FAQ问答系统的基本思想。

再进一步,如果用户提出的问题和FAQ数据集中的某个标准问题是相似问题,那么用户问题的答案就是该标准问题的答案。
基于前面所述的思想,我们为了提升检索模块的召回率,一般会在知识库中为每一个标准问句配置若干同义问句。问答系统的检索模块的召回能力和相似问句选择模块判断问句对是否相似的能力,是有限的,可能无法处理一些同义的表达方式。比如,一般的机器不知道“咋介可神木浪”(陕北方言)和“如何去神木”是同义关系。我们可以在后台为“如何去神木”存储一条同义问句,就可以回答陕北老铁的询问了。
4.3如何构建FAQ数据集
频繁问答对数据集的建设是一项系统工程——这里就不系统地讲了。
*先,我们需要根据场景特点,确定问题涉及的范围,比如领域、深度等。
然后,从开放获取的数据源、自有数据集中采集问答对数据。常见的数据源有百度知道、悟空问答等。找不到现成的问答对数据也没关系,我们可以基于知识图谱、表格数据、半结构化数据、非结构化数据来自动构建问答对;我们还可以人工编写问答对。
最后,设计一个机制,允许专家或用户持续地对FAQ数据集进行优化。常见的优化操作有,增加一个标准问题、删除一个标准问题、为一个标准问题增加同义问句、为一个标准问题删除同义问句等等。我们可以支持在系统后台直接进行优化操作,也可以在用户“点赞”等行为的统计数据基础上,自动、半自动地对数据进行优化。
5 FAQ问答的关键技术
我们可以计算用户query与每一个标准问句的相似度,然后选择相似度最高的作为相似问句,并向用户返回相应的答案。
但是,由于问答系统的频繁问答对数据集规模,一般是数百、数千甚至更大,这种方法的耗时非常大、不实用。我们可以学习搜索引擎的做法,将相似标准问题的寻找过程划分为两个阶段:(1)快速地从频繁问答对数据集中检索到一个较小的子集,保证这个子集以较高的概率包含了query的相似问句;(2)从前面获得的子集中,用一个(速度不一定快)效果较好的相似度模型,找出query的相似问句。
5.1检索模块
检索模块的任务,是以尽量低的时间消耗和尽量高的召回率,获取一个候选相似问句列表。我们可以使用一个计算复杂度很低的文本相似度算法,计算用户query与每一个标准问句的相似度,然后选出候选相似问句——这样做的耗时还是太高了。大部分检索模块采用倒排索引存储标准问句,并将检索任务划分为两个阶段:(1)从倒排索引中搜索一定数据量的,可能与query相似的标准问句;(2)从(1)中所得标准问句中,基于一个复杂度较低的文本相似度算法,选择k个与query 相似度最高的作为候选标准问句。
5.1.1基于倒排索引的信息检索
一般来说,我们可以以问句中的词语为倒排的key。
当数据量比较小的时候,我们可以自己实现一个倒排索引,并缓存在内存中使用。当数据量比较大,或需要支持并发查询的时候,我们一般会基于ES(Elasticsearch)把数据存储起来。
5.1.2召回阶段常用文本相似度模型
考虑到时间限制,这个计算可以使用的文本相似度模型比较少,一般是余弦相似度、杰卡德相似度、BM25等等。
5.1.3几个重要的词表
问句是一种非常短的文本,表示问句的特征非常稀疏、噪声的影响比较显著,因此针对问句的检索是一项困难的工作。举例来说,当用户提问“麟州在哪里”时,检索模块认为表4-1中1号标准问句、4号标准问句与query的相似度是相同的。如果问答对数据中有大量形如4号问句的标准问句,那么检索模块很有可能无法召回“神木在哪里?”这个问句。
为了缓解特征的稀疏性、减少噪声,我们通常会为检索模块配备同义词表和停用词表。
同义词表一般被用来对用户query进行改写,以获得用户query的更多同义表达形式,进而提升系统检索到相似标准问句的能力。
表5-1 同义词示例
序号标准词同义词1神木神木市、神木县、麟州2神湖红碱淖、红碱淖海子………表5-2 停用词示例
序号停用词1&2~……5.1.4两个重要指标
假设检索模块为N个query分别召回了K个候选相似标准问句。我们认为一次成功的召回时这样的:K个候选相似标准问句中,至少有一个是query的相似问句。那么,评价检索模块查询效果的核心指标,查全率的计算方式是:
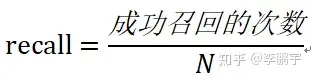
在实际应用中,我们不仅要考虑工具的效果,还应该关注工具的效率。判断一个检索模块是否优秀,还需要参考它的计算速度。我们想问答系统添加检索模块的主要目的,是大幅提升系统的响应速度。因此,我们希望检索模块具有较快的计算速度,消耗的时间远小于标准问题选择模块。如何度量检索模块的计算速度呢?检索模块为一个query完成检索任务的平均耗时,反映了它的速度。平均耗时的计算方式为:

如何判断检索模块是否足够快呢?我还没想好。
5.2问句分类
为了进一步提升检索模块的速度和精度,我们有时候还会对问句进行分类。比如我们按照手机银行用户的查询意图,将问句分为“储蓄卡办理”“储蓄卡挂失”等类别——当用户提问“储蓄卡丢了怎么办”的时候,系统会判定query的意图类别为“储蓄卡挂失”,然后使用检索模块从FAQ的“储蓄卡挂失”类中检索候选标准问句。
在这个环节,我们一般兼顾分类算法的效率和效果。
5.3相似标准问题选择模块
标准问题选择模块的主要任务,是基于文本相似度模型,从检索模块召回的K个候选相似问句中,找到与用户query最相似的那一个。该模块的核心,是一个效果较好的文本相似度模型。
5.3.1重排序阶段常用的文本相似度模型
这部分内容可参考
5.3.2最相似的问句就一定是同义问句吗?
不论检索模块为query召回的候选相似问句质量如何,相似标准问题选择模块都会为query找到一个相似度“最高”的标准问句。那么,这个“最相似”的标准问句,一定是用户query的相似问句,即与用户query同义吗?不一定。假设检索模块为“神木在哪里?”召回的候选标准问句如表5-3所示。与query最相似的是2号问句,而二者含义明显不同。这时候,我们如果把“桃花源在哪里?”的答案返回给用户,会显著地影响用户体验,导致我们收到如图5-1的评价。
表5-3 若干问句
序号问句2桃花源在哪里?3你老家是西山吗?4你老家是西山,不是山西?
如何避免做出不合理的回答呢?我们可以为文本相似度配置一个阈值,当两篇文档的相似度超过阈值,判定二者同义。这种方法可以帮助我们减少前面所述的错误情况——还有一些策略可以提供类似能力,比如为有监督的文本相似度模型增加一个表示置信度的输出。
5.4几个重要指标
相似标准问题选择模块的任务是,以较高的查全率和查准率,找出K个候选相似问句中,与用户query相似的那一个。
6 FAQ问答的应用
6.1什么时候可以考虑使用FAQ问答系统
FAQ问答系统的优势是:(1)以自然语言文本为输入,给用户以非常高的自由度;(2)直接向用户返回答案,以较高的检索精度为用户节省时间资源。
福兮祸之所倚——FAQ问答系统的劣势是:(1)我们的表达方式差异可能非常大,往往导致相似标准问句选择模块效果较差;(2)频繁问答对数据集的构建成本是比较大的,我们无法为一个或多个知识面非常广的领域构建FAQ问答系统。
综上所述,在封闭领域,即知识范围相对有限的情况下,大家在设计问答系统时,会*先考虑基于FAQ的策略。
6.2生活里常用的FAQ问答系统
我们生活里常用的购物网站或APP,几乎都有智能客服。这些工具的用户量非常大,而场景相对聚焦、知识量有限,非常适合基于FAQ问答系统对用户群体的高频问题进行处理。如图6-1,是一个采用了FAQ问答策略的机器人,可以回答银行相关业务中的各种常见问题。

6.3 FAQ问答系统的价值
统计学里,大家总说正态分布是最普遍存在的一种分布,别的都是菜鸡。实际上,在生活里,我们最常遇到的是幂律分布——大家的收入、词语被使用的频次、各人在社交媒体中的粉丝数、关注各种问题的人数等等,都服从幂律分布。幂律分布的通俗叫法,是“二八分布”(虎扑JRs可能非常喜欢这个名字),即少数成员持有大多影响力。
购物网站或APP等工具对应的场景里,各个问题或知识点被关注的热度分布服从幂律分布。热度较高的问题,比如“储蓄卡怎么挂失”,用户群体会以非常高的频率向人工客服提出咨询请求。在人工客服工作的过程中,我们可以不断地发掘高频问题,并提交给FAQ问答系统,这样答疑的工作量就逐渐地转移到了机器身上。FAQ问答系统完成的答疑任务越多,它创造的价值就越大。
7结语
作为一个人工智能领域的从业者,一个脑力无产者,任务是创造用来争夺阶级兄弟姐妹们岗位的机器,我也是有点郁闷。
好消息是,在可见的未来,智能客服会一直需要和人工(客服)协作完成任务。一些问题处理起来相对复杂,机器难以胜任,比如安抚一个不知道怎么挂失储蓄卡的暴躁老哥,必需由人工客服接管,因此这种转移不会是彻底的。考虑到机器和人各自的优势,即机器不知疲倦、可以稳定地回答简答问题,而人可以在体力、脑力、情绪资源允许的情况下解决比较复杂的问题,智能客服和人工客服可以协作起来,以整体更高的效率和效果,为客户答疑解难。
注意:本文为李鹏宇(知乎个人主页https://www.zhihu.com/people/py-li-34)原创作品,受到著作权相关法规的保护。如需引用、转载,请注明来源信息:(1)作者名,即“李鹏宇”;(2)原始网页链接,即当前页面地址。如有疑问,可发邮件至我的邮箱:lipengyuer@126.com。
参考文献
毛先领, 李晓明. 问答系统研究综述[J]. 计算机科学与探索, 2012.
梁敬东, 崔丙剑, 姜海燕, et al. 基于word2vec和LSTM的句子相似度计算及其在水稻FAQ问答系统中的应用[J]. 南京农业大学学报, 2018, 41(05):178-185.
侯丽敏, 宋纳红, 魏庆. 基于远程教学领域的FAQ问答系统研究[J]. 郑州轻工业学院学报(自然科学版), 2008, 23(003):69-72.
免责声明:本站所有内容及图片均采集来源于网络,并无商业使用,如若侵权请联系删除。
上一篇:铜川seo优化公司
下一篇:成都网站定制开发
