


什么是谷歌技术SEO? 2023年最佳实践指南(零技术背景也能做好)
有不少人和我聊过,觉得google技术seo这块比较难 ,尤其是涉及到代码部分。事实上,大多数常用到的技术seo,对技术的要求并不高 ,即使你是文科背景,也可以很轻松上手。
觉得难的背后,我认为跟工作环境会有很大的关系:缺乏锻炼的机会。比如像我所在的公司,主推一个官方独立站。作为营销团队里最懂seo的我,在加入公司后就已经把所有技术seo不规范的地方都整了一遍;后续谷歌算法更新或者是网站升级遇到的技术性问题,自然而然地大家都是默认找我来处理。这就会形成这样的一种局面:后面新进来的seo, 她们更多只要做好内容、外链和品牌声誉度建设即可。因此,要更好地掌握技术seo, 还是要加以实践。愿看完这篇文章的人,都能够有所行动。
一. 谷歌技术SEO是什么,为什么重要
SEO工作通常被会划分为On-Page SEO、Off-Page SEO和Technical SEO三大部分。
On-Page的重点是内容的质量,Off-Page的重点是外链和品牌声誉度,而Technical的重点是网站的架构和技术,它使搜索引擎爬虫更容易有效地爬取并索引网站的每个页面,以及给用户提供友好的浏览体验。
举个例子方便更好理解技术seo的重要性:你写了一篇质量非常高的文章,但这篇文章却错误地设置了一个noindex标签,搜索引擎就不会去收录它,从而无法获得seo排名和流量。外部有个大V转发分享了你这篇文章,并且给出了指向原文的链接,但由于你的网站访问速度非常慢,用户进来后发现老半天页面都加载不出来就离开了。这些都是由于技术没有处理好导致机会的错失。
下面这张图来自SEMRUSH,不够完整,但还是可以帮助快速粗略地了解到各个部分的主要优化点在哪里。

谷歌技术SEO涉及到的范围很广,在这里我主要给大家普及有哪些seo技术点是重要的,为什么重要,以及通过例子加以说明如何应用。每一个技术点要完全地掌握,涉及到的知识会很多,大家需要在实践中再深化。文章很长,已经有一定基础的同学,可以通过目录快速导航到你们不够了解的领域。
二. 盘点常用的12个技术SEO点
1. robots.txt 文件
如果你的网站有robots文件,那谷歌进入网站时会第一个去爬它。robots.txt 文件的作用是告诉搜索引擎抓取工具可以访问你网站上的哪些网址。
robots文件不是必须要有的,如果你想让搜索引擎访问你网站上所有页面,那就可以不设置robots文件。但我会建议要有,因为robots文件可以有效地阻止谷歌去抓取相似的页面,以及通过屏蔽不重要的网页以降低服务器的负荷。
举两个例子:
广告投放人员复制了一个商品页出来做A/B test, 只是改变了一个特别重要的变量,页面内容是高度重复的。这种情况,很明显我们是不希望搜索引擎去抓高度重复的B页面。那我们就可以把所有用于做广告测试的B网页放到一个 http://xxx.com/ad/的目录下,再通过robots文件把ad目录下的所有页面进行屏蔽。不计划做SEO、禁掉也不影响SEO的网页,那就可以通过robots.txt文件去屏蔽它,降低蜘蛛爬行网站时的服务器负荷。robots.txt一定是位于根目录下,URL是http://xxx.com/robots.txt。看到这里,你不妨现在就试试通过在竞争对手的域名后面加上robots.txt,看看他们都屏蔽了哪些网页。
我们来看看Anker的robots页面 https://www.anker.com/robots.txt

解读过来就是:Anker允许所有搜索引擎蜘蛛爬行除了URL中带有/coming-soon以外的网页。
需要注意: 编进robots.txt 文件屏蔽的网页仍然可能会被编入索引。如果谷歌发现有其它网站给了链接到某个被robots屏蔽的网页,就还是很有可能会继续索引它。如果要完全阻止,需要使用 noindex 元标记。接下来我们就讲讲noindex是如何使用的。
2. noindex元标记
noindex 标签的作用是告诉搜索引擎不要去索引和不要在搜索结果中呈现该页面。加了这个标签的页面就可以真正放心是完全屏蔽的了。
添加方法很简单,直接在要屏蔽的页面HTML的head部增加下面这行代码:
<meta name="robots" content="noindex,nofollow" />
记住一定要放到 <head> 部才能生效。
反之,正常要做排名的网页,它的robots标签是这样的:
<meta name="robots" content="index,follow" />
3. XML sitemap文件
很多网站的robots.txt文件最后一行代码是指向本站的sitemap文件,比如我们来看Shein的robots文件的最后一行代码 https://www.shein.com/robots.txt
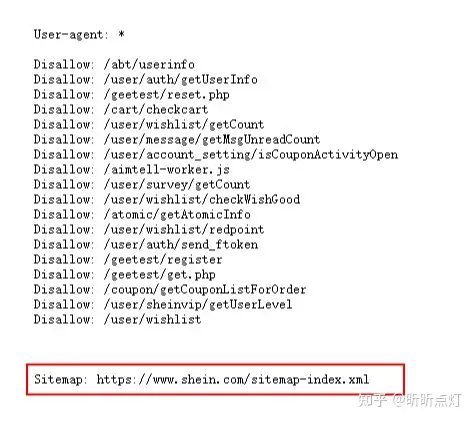
如果这样做,搜索引擎爬行的第二个页面就是sitemap。那sitemap是有多重要呢?
其实sitemap和robots文件都不是网站必须的。如果你的网站规模很小(谷歌给的定义是网页数量<500)且内部已经全面建立链接,那可以不需要站点地图。国外很多规模小的B端企业网站是单页的,那么他们自然就不需要sitemap了。
我建议除了单页网站以外,最好还是要有网站地图。网站地图的作用就相当于给到谷歌一个指引,告诉谷歌网站上有哪些网页。从我自己的实践来看,网站地图给我带来的好处是可以加快收录和保证收录。
加快收录这个很好理解。保证收录这块我讲一个自己的经历。有一次领导给我发了一个我从来没见过的产品页面(我们网站有几千个SKU),问我为什么在谷歌搜不到这个页面。我查了下,发现这个页面确实没有被谷歌收录,推测原因是很多年前批量上的一个产品,产品很一般,上线以来都没什么访问量,也没有外面的网站给它链接。于是我把这个产品链接加入到sitemap里,两天后就能在谷歌搜到它了。
sitemap可以通过网站插件,或者第三方的sitemap工具生成。
注意:网站的sitemap有两种。一种是给搜索引擎看的,URL后缀是.xml;一种是给用户看的,URL后缀通常是.html。给搜索引擎看的sitemap长下面这个样子:
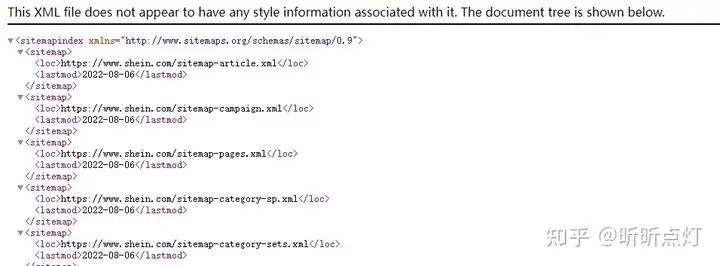
4. 网站速度
网页的加载速度是影响SEO排名的重要因素,所以作为一名SEO推广人员,有责任定时监测网页速度,指标不良时需向IT人员提出优化需求。
英文SEO常用的网页速度测试工具是PageSpeed Insights :
还是以anker为例,通过PageSpeed Insights测出来的结果如下图:
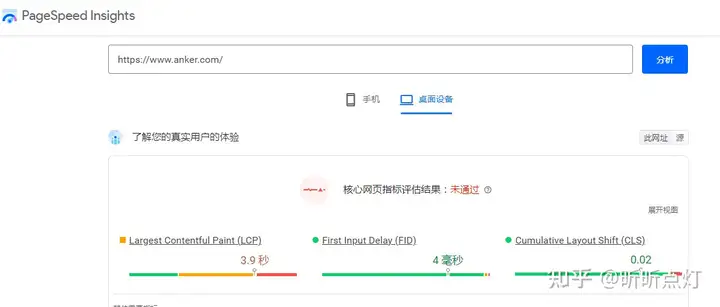
这个工具同时还会在后面给出具体的提高速度的优化建议

不懂技术没关系,这个不是我们SEO人员必须要懂的东西,只要把测试的结果页面发给IT技术一起来沟通如何改善。
通常来说,图片和服务器对速度的影响是最大的。所以需要跟产品上架人员多强调注意图片的大小,单个图片尽可能控制在100kb以下,不重要的图片甚至可以控制在30kb以下。
5. 结构化数据
结构化数据可以让 Google 更轻松地了解你的页面和产品内容,以及让谷歌为你的网页创建丰富的搜索结果摘要成为可能。为什么说是成为可能呢?谷歌是不会保证,添加了结构化数据就一定会呈现丰富摘要。但如果你不去做这件事,那就一定不会有。
下图红圈中的富媒体结果就是通过结构化数据来实现的:
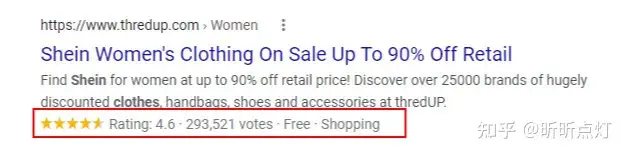
丰富的摘要能够提高点击率,为你带来更多的SEO流量。同时点击率的提高会间接影响提升SEO排名!
如果还没有添加SEO结构化数据,马上去找你们的网站开发人员。结构化数据的配置通常可以通过网站插件快速实现 ;如果找不到合适的插件,可把谷歌官方的教程发给开发人员。
6. 404页面
404页面指示了页面已经不存在了的状态。404页面会带来糟糕的用户体验,还会损害网站的完整性并干扰 Google 抓取和访问该网站的能力。短时间内网站涌现出大量的404页面更是会直接影响到SEO排名。
产生404页面的原因有很多,每个公司的环境不一样会有所差异。比如把已经EOL的商品直接下架了;类目调整,原来的一些分类不存在了;URL的生成规则是调用产品名称,当改动产品名称URL也会随之改变等等。这里会建议把常见引发404页面的原因整理出来,给到相关的运营人员,以便在做改动网站的时候注意规避。
404页面是有意义的,不能完全否决它。也就是说, 我们允许有少量的404页面存在,但是要控制它占非常低的比例,并且在404页面做好网站下一步的访问指引。
通常我对于404页面的处理方法如下:
因为操作错误引起的, 联系相关人员恢复;必须下线的页面 ,做301重定向跳到相关的同类页面或*页;如果没有很好的跳转指向,同时该网页也不重要,那就以404页面存在。7. 301重定向和302跳转
SEO人员大多对301和302不陌生。那这两者的区别是什么,和怎么用呢?
301重定向是永久定向,常用于域名的跳转,它是能够把网页之前积累的大部分权重传递到新的网址。而302跳转是暂时性,不会传递权重,实际应用也不多。
可以利用第三方工具来查询页面是301还是302状态
建议重点要做SEO排名的页面尽可能避免做301跳转。我有个重点在推的页面,在做了301跳转后(只是单纯更改了URL,页面内容不变)排名直接从前三名下降到第五名之后。而且页面所推的关键字外部竞争越激烈,做跳转对排名的影响就越明显。
8. Canonical标签
Canonical也是SEO常用到的标签,它通常用在当网站上有多个URL的内容是相同或者高度重复时,可以通过Canonical标签告诉搜索引擎你希望哪个版本的URL出现在搜索结果中,避免权重分散。
和noindex标签一样,canonical标签也是要放置在网页的 <head> 部分中,代码如下:
<link rel="canonical" href="https://example.com/sample-page/" />
代码里的链接就是要出现在搜索结果中的页面。
下图是随便找的一个英文网站的canonical标签截图以供参考:
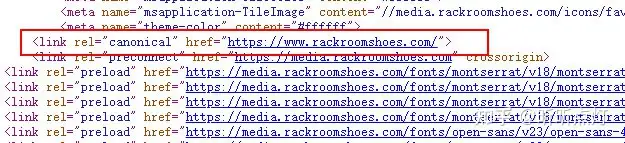
在我刚入行的时候,谷歌会严格遵守canonical标签指令。然而半年前,我在帮一个女孩子debug新页面不收录的问题时,发现canonical tag很有可能会因为谷歌判定两个页面的重复度不高,从而不生效。关于这件事,我特意做了一些研究,有兴趣的可以点击这里了解更多。
9. HTTPS安全协议
https安全协议是一个轻量级的排名信号,如果你的网站是http, 谷歌也会索引。但https的重要性更多体现在给用户在浏览网站时获得安全的体验。
曾经有一次我们的网站付款页流失率突然飙升。经过排查后,发现问题出在付款页的某个改版动作导致付款页网址从https变成了http。很多浏览器对http页面都会有安全警告的提示,客户就会担心在当前页面付款有很大的安全隐患从而流失。在修复了https后,我们的付款页流失率也恢复了正常。
现在基本所有的商业化网站都已经从http升级为https。如果你的网站,或者有某些网页还没有升级,那是时候动手了。
10. Google Search Console
Google Search Google是谷歌官方出的、对监控SEO流量效果和网站性能有非常大帮助的一款工具。
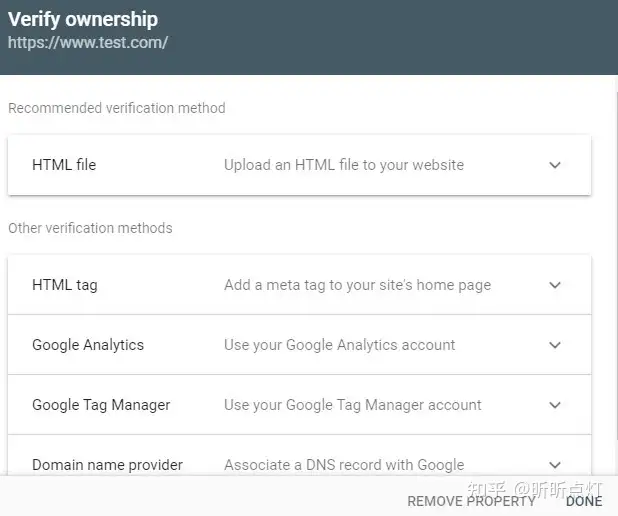
我发现很多初级的SEO用这款工具比较少,甚至是不知道有这么一款工具。 如果你的网站还没有配置Google Search Google, 可通过访问网址 https://search.google.com/search-console,根据相应的指示进行安装部署。
验证Google Search Console的方法有很多种,甚至可以通过Google Tag Manager进行验证,具体看下图:
11. Google Tag Manager(GTM)
Google Tag Manager是一个代码标签管理系统,通过它可以部署各种网站跟踪代码。特点是功能非常强大、可以实现快速、轻松、大量部署,同时*大地减少网站代码冗余。
我们常用的Google Analytics也可以通过Google Tag Manager进行部署。我第一次接触Google Tag Manager是为了给GA配置增强型电商。配置增强型电商对于我来说还是挺复杂的,所以当时去请了懂这块的数据专家和公司的IT配合一起来部署。配置好后,我自己学着来摸索使用,发现GTM真的太方便、太好用了!尤其是需要在部署各种广告平台的跟踪代码时,自己就能轻松地在GTM后台操作,不需要麻烦开发的小哥。
如果你还没在用Google Tag Manager, 强烈推荐。先从简单的开始,代码部分觉得复杂的话,那就请教下网站开发小哥。
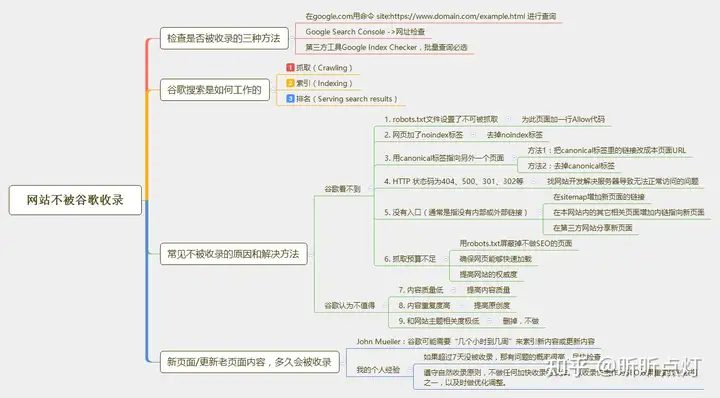
12. 新网页、旧内容更新没有被收录,如何排查和实现收录
这里涉及到的技术SEO知识是,你要去了解Google是如何进行页面抓取、索引和排名的。
网页无法被抓取,就不可能进入索引阶段。而网页不被抓取的原因可能是我们上面提到的robots.txt, noindex, 404, canonical标签等技术SEO引发的。
网页被索引了,不代表一定会有排名,这里跟On-Page SEO的关系很大。
这是一个相对比较大的话题,有兴趣的可以看我另外一篇专门讲如何解决页面不被谷歌收录的文章。如果上面提到的技术SEO知识点你已经掌握得比较好了,直接看下面这张整理了要点的思维图:
三. 一些学习谷歌技术SEO的建议
以上的分享都是我在SEO工作中常用到的,但由于使用情景较多从而无法一一细数和讲得非常深入 。希望通过提供几个学习技术SEO的思路,能够帮助你们进一步理解和延伸:
Google搜索中心是一个非常好的全面学习平台: https://developers.google.com/search/docsSEO是动态的,比如我前面举例的canonical标签,从以前的100%生效变成了现在的当页面相似度不是很高时不起作用。因此需要关注SEO的最新变化,不断更新你的SEO知识。很多SEO技术的问题需要借助网站开发人员的协助,所以平时跟他们打好交道;还可以通过建立一些网站的SEO规范文档给到开发人员,能够有效地规避因网站改动出现SEO不规范问题。关于技术SEO,我也是在工作中边学边运用。掌握后发现其实并不难,真的,这事零技术基础也能做得很好。
如果你在做技术SEO时有不一样的应用心得,或者想要补充除了以上提到的12点以外的技术点,欢迎留言交流。
免责声明:本站所有内容及图片均采集来源于网络,并无商业使用,如若侵权请联系删除。
