


再让AI大厂这么“偷”下去,咱可能就看不到免费的网站了。。。
原标题:再让AI大厂这么“偷”下去,咱可能就看不到免费的网站了。。。
几天前,谷歌突然更新了隐私政策,明确表示要用网上所有的公开数据,来训练自家的 AI 模型。
也就是说,根据新政策,你在网上公开发布的任何信息都有可能被谷歌抓取,包括但不限于你发的帖子、搜索的关键词以及看过的视频。
这不妥妥互联网裸奔吗!
OpenAI 前脚刚被起诉数据侵权还没多久,谷歌就马上着急来撞枪口。
在这个节骨眼上整这么一出,大概率跟数据收费脱不了关系, 谷歌再不薅这波免费的羊毛,之后很有可能就薅不到咯。
这事儿啊,自打 ChatGPT 爆火后再也没消停过。
世超先给大家伙儿捋捋时间线。
今年 3 月的时候呢,马斯克带头打响了数据收费第一枪,宣称推特的 API 接口不再免费了。

紧接着, 美版贴吧 Reddit 也按耐不住了。
上个月 Reddit 闹得沸沸扬扬的 “ 停电 ” 运动,就是为了抗议官方的 API 收费政策。
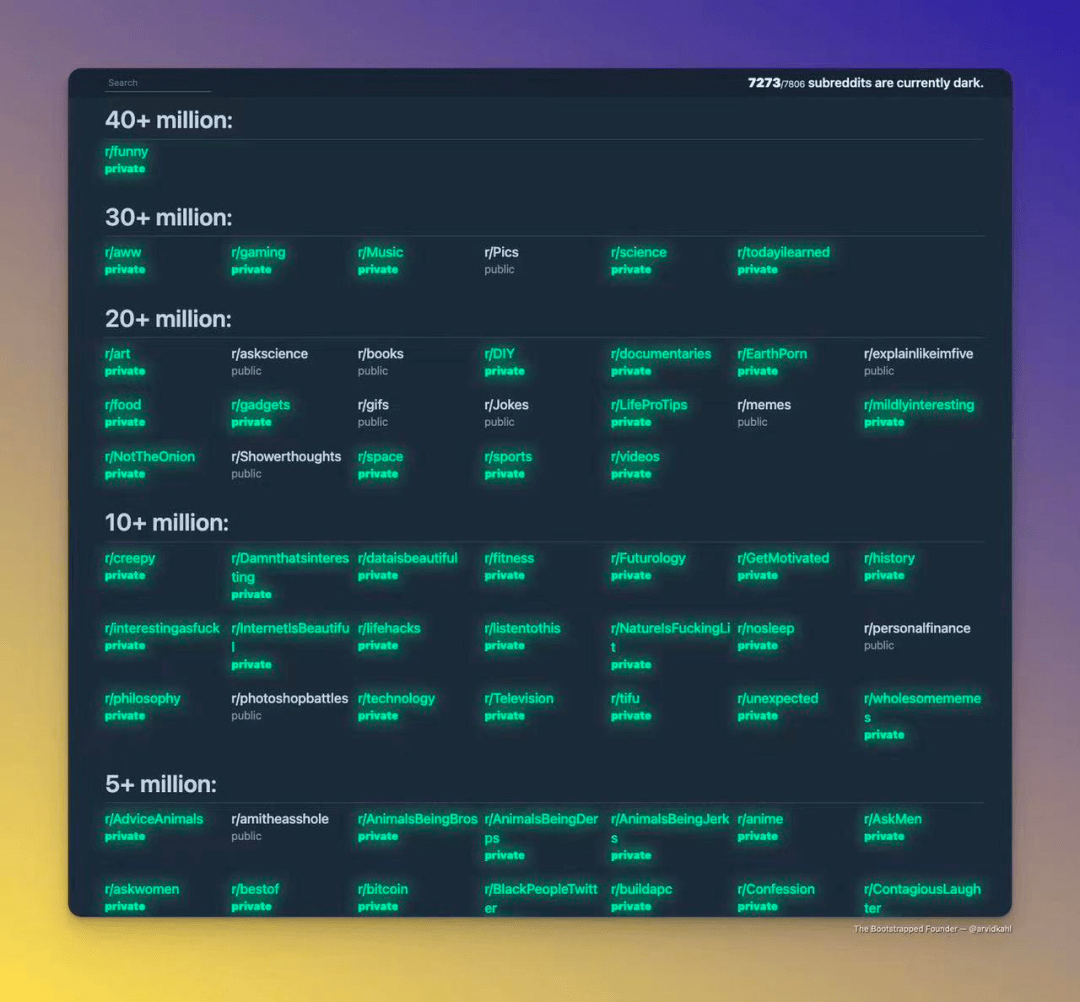
之前世超写这事儿的时候还在猜测, Reddit 官方最后会不会作出让步。
从现在的后续看来,大多第三方软件已经确认关停, Reddit 是铁了心要数据收费。
再到这段时间,推特又整了限流的幺蛾子,没有花钱认证的帐号每天就只能阅读 600 条贴文,目的呢也是为了防止机器人抓取用户数据。
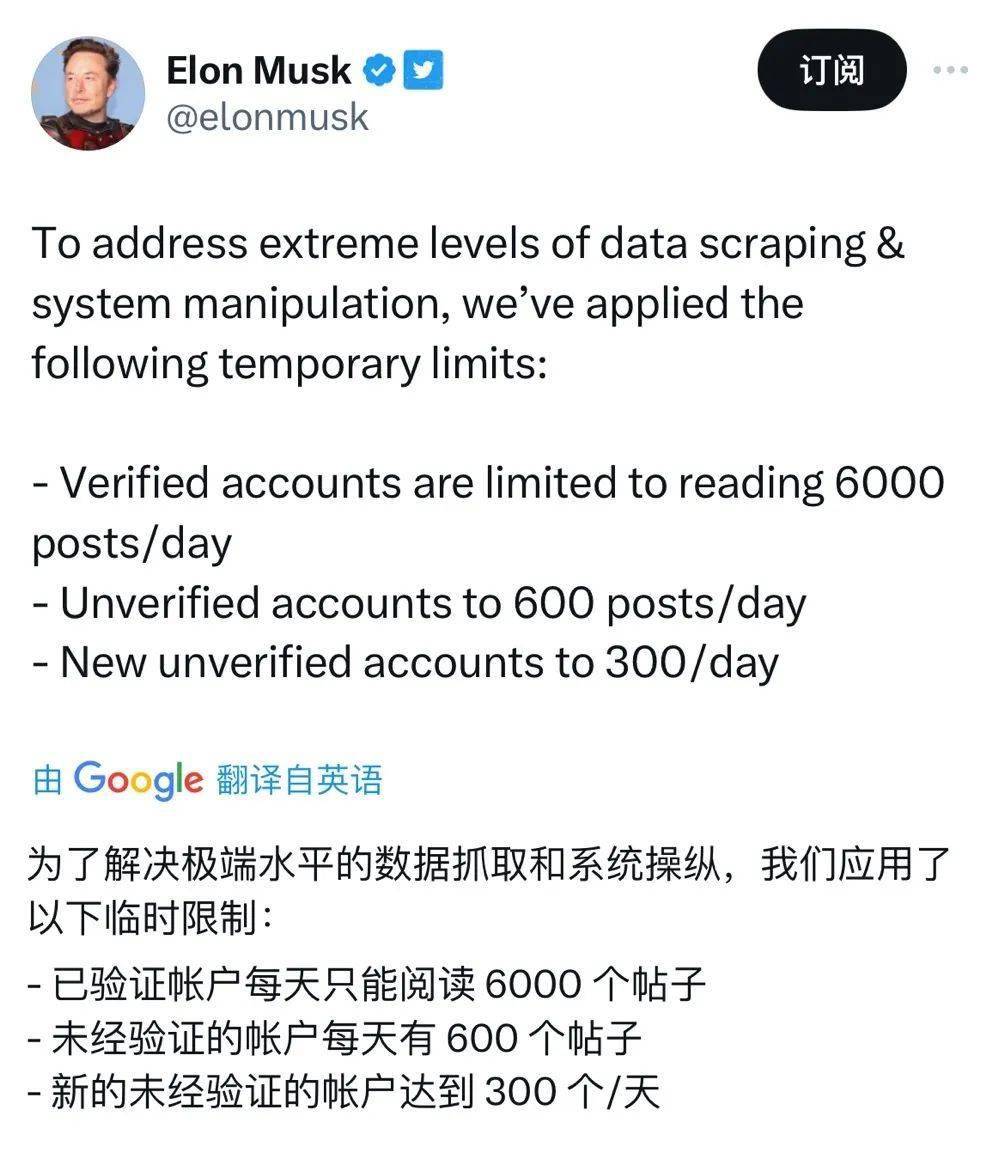
难道数据就这么值钱吗?
世超觉着啊,还是 AI 的锅。

AI 大模型要想变得更聪明,就需要源源不断的数据去 “ 喂养 ” 。
现在能做大模型的,要不就是自己家有数据,像百度、阿里和腾讯;要不就是爬人家的数据,这里点名 OpenAI 。
因为很多网站都开放有免费的 API 接口,才给了微软、 OpenAI 这些巨头可乘之机。
但今时不同往日, AI 在重新赋予数据价值以后,有筹码在手上的平台当然 不乐意被白嫖了。
甚至于 Reddit 的 CEO 霍夫曼都把话搬上明面儿了:就是不想免费提供数据给巨头们。

所以, OpenAI 被起诉估计也是平台们联合起来想要 “ 杀鸡儆猴 ”, 治一治 AI 的这股歪风邪气。
不过,法律这次会不会站在 OpenAI 这边,还真不好说。

因为数据版权涉及到 3 个关键的问题:
1.数据爬虫的行为本身是否是合法的?
2.数据是否受到版权的保护?
3.用数据生成的作品是否受到版权保护?
*先第一个问题,要获取数据,无非就是付费购买,或者收集网上公开的数据。
但需要注意的是, 公开的数据并不能等同于授权使用,而且还要看网站是不是有相关的条款对数据爬虫行为做出了限制。

要是直接越过版权方的同意,或者绕过了网站限制强行获取数据,那就是妥妥的非法获取计算机信息系统数据罪。
即使 OpenAI 声称爬的是公开网站的数据,数据爬虫行为本身是否合法,还要看版权方是不是给了授权。
其次,关于 数据本身是否受到版权保护。
根据美国的版权法,如果 AI 模型训练所用的数据符合 “ 合理使用 ” 的范围,那就不会构成侵权。
但问题就出在这 “ 合理使用” 上。

“ 合理使用 ” 的构成要件包括是否涉及商用、作品本身是否受版权法保护、所使用部分的数量以及使用之后对作品本身造成的影响这四个标准。
像什么新闻报道、学术研究,适当引用是完全 ok 的。
可 AI 模型上亿万级别的数据使用量、已经商业化的 AI 软件,还能算作 “ 合理使用 ” 吗?
最后,就是 AI 生成作品的版权问题。
因为训练数据版权理不清, AI 生成的内容自然也会存在版权争议。前几天, Steam 还下架了一款使用了 AIGC 生成的游戏,理由就是版权有问题。

咱就拿 AI 绘画举例子,图像生成相当于一个拆分又重组的过程,虽然最后的结果是完全 “ 新 ” 的,但仍然会保留训练图像的某些特征。
但这种情况到底算不算侵权,各国的说法现在也是众说纷纭。
因为训练数据是人家的,美国版权局认定 AI 生成的作品不受版权法保护,甚至还可能侵犯著作权。
而日本政府的态度则截然不同,表示日本法律不保护 AI 训练所用数据的版权。

至少在现行的法律框架下,上面这些问题很难得到一个统一的答案。
既然监管不给力,那版权方就只有提刀自己干了,该收费的收费,该追偿的也赶紧追偿。
▼OpenAI 被起诉的文件

可以预见,在推特和 Reddit 之后,可能还会有更多的内容版权方竖起高墙。
这事儿呢,对于平台来说,当然是个挣钱的新路子,科技巨头再不济也就是多砸点儿钱。
但对于整个互联网来说,可算不上一件好事儿。
当年,互联网就是带着开放共享的基因出生的,像什么维基百科、推特,之前常年免费提供 API 接口,开发者调用数据很方便。
但现在如果让数据收费这么一搞,结果会怎么样还真不好说。
毕竟,小开发者没有支付巨额数据费的能力,如果创新只在巨头里发生,这不就是纯纯搞垄断了?
最主要的是,可能很多现在免费能看到的网站之后就要花钱才能看了,这才是对咱们这种普通用户的真实暴击。

其实吧,数据收费这事儿也不能全怪平台,实在是让 AI 巨头给 “ 抢 ” 怕了,算是一种自保的无奈之举。
虽然这次谷歌有“隐私政策”护体,但结果如何还真不好说。
所以,关键还要是看监管的大锤什么时候能落下。
厘清数据版权,是 AI 要发展始终绕不过去的一道坎儿,而现在,似乎也同样关乎着互联网的未来走向。
不知道 AI 这艘船,会将我们推向一个更开放,还是更封闭的时代?
撰文:糖醋排骨 编辑:江江&面线 封面:焕妍
图片、资料来源:
推特、谷歌
金杜律师事务所, CHATGPT 许可应用,知识产权和数据怎么看?
21 世纪经济报道, AIGC 爆火之后:如何平衡数据流动共享与安全保护?
链科天下, OpenAI 遭集体诉讼,明星大模型变 “ 数据小偷 ” ?
知乎, AI 数据合规系列文章( 二 )——数据获取的合规风险
己任律师事务所,浅析数据爬取行为的刑事风险及防范思路返回搜狐,查看更多
责任编辑:
免责声明:本站所有内容及图片均采集来源于网络,并无商业使用,如若侵权请联系删除。
上一篇:ChatGPT暂停接入必应搜索功能孙悟空曾打死6个凡人,为何还能被封佛?看这6人名字连起来念啥
下一篇:陌路遥 篇一:worepress网站搭建步骤总结,很实用的概括了(小白总结)原来“睡觉戏”是这么拍的,真是辛苦演员了!网友:这怎么忍得住!
