


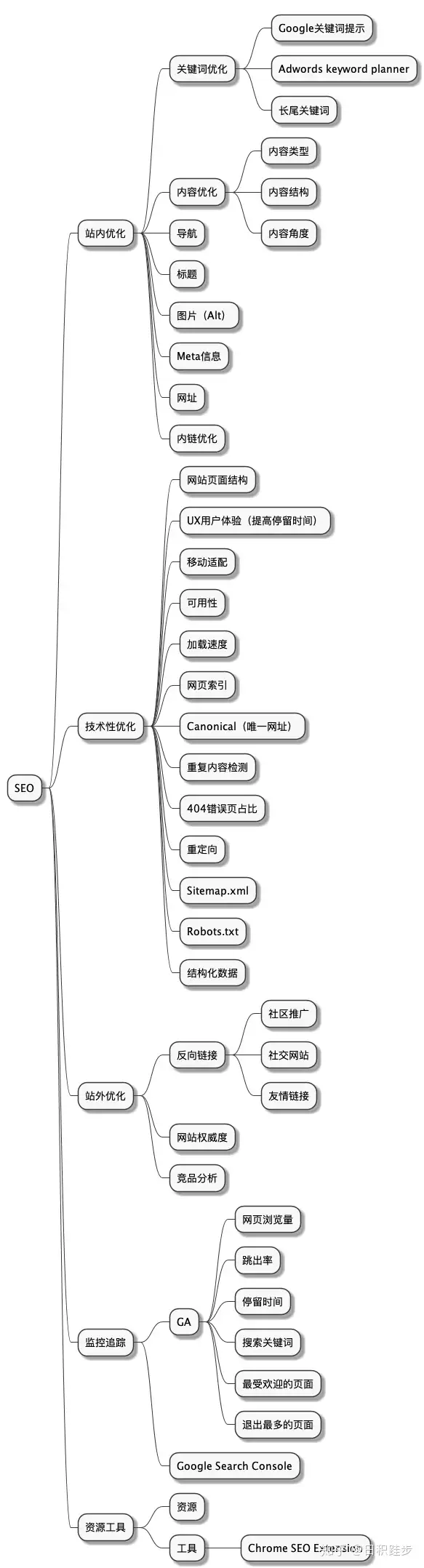
什么是SEO
原文*发自我的博客:
IF YOU BLOG, BLOG FOR GOOGLE
在《什么是互联网广告》中提到SEO属于网络营销的一种,而营销推广在整个商品生产流通的过程中又如下图所示:
网络营销中有两个很大的分类,分别为付费的广告和免费的SEO,SEO的好处在于:免费流量,被动访问,源源不断。
在内容营销日渐成为主流的今天,内容的传播和增长一定会更多的依靠搜索引擎(一般是谷歌/YouTube/社交网站等)。普通大众都是搜索引擎的用户,通过主动输入“关键词”后得到的信息一般更加符合自己的搜索需求,而非通过社媒广告或搜索广告等渠道的被动“投喂”,这也是为什么SEO流量价值较高的原因。SEO & Content Marketing,这两个词很早就结合在一起了。1
SEO 之前
在新建一个网站之前,*先你要:
找到一个Niche(细分领域)市场,最好是垂直的内容而不是大杂烩。调研这个Niche市场的竞品,了解这些竞品网站的月PV规模,是否有大站或小站,流量季节性波动是否很大,外链是否比较容易获取,是否可以通过销售虚拟或实体商品获利,从而了解这个Niche市场的规模。逆向查出这类竞品的核心关键词,调研这些核心关键词的月搜索量、竞争度(KD)、同类词(Having same terms)及对搜索结果第一页(SERP)的网站分析(比如查看DR-网站权威度)。购买域名。在开始一个新站之前,一定要查查你购买的域名是否有黑历史,可以通过查看域名的反向链接是否为空来判断,如果有反向链接,那还是换一个干净的域名。也可通过Wayback Machine查看网站黑历史。如果以上问题你都研究清楚了,也对自己的站具体做啥有大体的规划,那就可以正式开始SEO之旅了。
SEO 过程
站内优化
SEO的一个大头就是做好站内优化,主要任务就是让网站的内容更有竞争力,让内容围绕我们的核心关键词关联,同时能让搜索引擎的爬虫能很容易的获取我们网站的内容。
内容优化
在优化内容前,让我们先思考这样一个问题:为什么我们的文章是受欢迎的?
Google一直在致力于提高搜索质量,这意味着Google一直想通过关键词去理解用户的搜索意图。比如我们要搜索x vs y、what is x与xyz in 2020这类关键词的时候,我们可以查看排名前几的网页,思考下为什么这些页面会排到最前面。
可以从排名前几网页的以下三个维度去分析:
内容类型:博客?落地页?论坛社区?产品页?导航页?内容结构:是教程类?问答类?观点类?资讯类?内容角度:是否有共同的主题?比如全部都是xx%的折扣类或后面都带年份的,后者常见于评测类关键词。如果想了解更多和搜索意图相关的信息,可以参考这篇:《Search Intent: The Overlooked ‘Ranking Factor’ You Should Be Optimizing for in 2019》。
关键词优化
为什么要做关键词优化?因为流量的来源在于关键词,我们人类是用语言交流的,搜索也是用词来搜索的,当我们打开搜索引擎的时候我们一般都是用几个词去搜索我们要的内容,这是我们主动获取信息的主要方式,另外一种获取信息的方式是被动获取,譬如抖音和头条这种Feed信息流推荐。
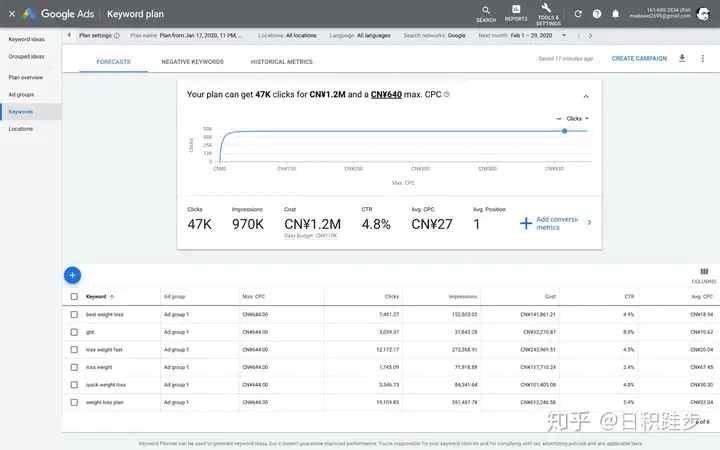
所以我们的内容要围绕关键词而写作,全文中关键词的数量应该比较多才好,而且这个关键词的月搜索量应该高一些,竞争度应该低一些,这样排名好做,流量容易起来。使用Google关键词规划工具发掘竞争对手网站、博客的关键词分布,发掘未被发现的关键词,获取这部分词的流量。
围绕品牌关键词优化,因为品牌关键词的搜索量大,竞争度可能还低,弊端在于你永远不可能排名到前三,比如如果你写Google search console相关的文章,前6名都是http://Google.com,但是每月的引流人数依旧不错。Google喜欢品牌胜过域名、关键词、反向链接等。
如果做关键词优化?
Google关键词提示:

标题
标题很重要,最好能包含你要做的关键词。当然不是要你做标题党,标题党更适合社交媒体如微信公众号这类,更能骗取用户从而提高打开率。标题党不适合SEO这类流量,因为这是用户搜索而来的,为SEO而做的文章更应考虑用户的搜索意图。
Meta信息
Meta信息号称TKD元描述,就是Title/Description/Keyword,这是SEO*要关注的三个点,也是网站建设过程中重点考虑的一个方面。如何查看一个网站的Meta信息?最方便的就是安装Chrome的一个插件:meta seo inspector

网址
网址最好使用静态类的网址,不要全部都是数字组成或者包含动态参数那种网址,这类一般是动态网站,就是页面是由服务器实时通过服务器的数据生成的页面,不少内容还是由浏览器脚本(Javascript)与服务器通讯处理后生成的,这种对爬虫很不友好,最好使用服务器端渲染好的网站架构。
长尾关键词
长尾关键词一般是由多个词组合而成的,它的特点就是单个长尾词的流量可能月搜索只有几十个,但是这类长尾词数量众多且一般都是多个相关内容的词组合,竞争度还很低,如果能获取到长尾词的流量,聚合起来也是很多的。不过博客一般由于内容少,并不适合做长尾词,一般大的内容站适合去建设长尾词。以之前我做过的一个流量站而言:
对上百万PV的流量来源进行分析,一共有65万个页面。以流量获取最多的前5千页面分析(占总页面近1%,获取流量占总流量近10%),Tag词页面占据了近92%的数量,可以说大部分流量都来自Tag页面,而这4600多Tag页面的获取流量中位数是19,平均数是30。也就是说大部分页面只获取了十几个浏览量,流量完全靠页面数量积累起来,而Tag页面本身获取流量的核心就在于Tag词,是这近4000个词获取了十几万的PV。导航
导航一般是面包屑导航,比如下面这种:

导航如果做不好,用户体验就会下降,跳出率会高,停留时间会降低,最后可能会影响我们网站的排名。
内链优化
内链优化的有助于我们给站内不同的页面导流,传递页面权重。比如我们博客常见的“你可能想看的文章”这类,就是丰富内链。如果你发现一个页面的流量非常高,而一个页面的流量很差,如果这两个文章还存在一定关系,那你可以在流量高的页面给流量低的页面导流。
图片
图片最好加ALT标签,这样如果ALT标签包含一些关键词的话,还可能会带来一部分流量。当然ALT标签也可以在网络加载图片失败的时候让用户能够看到这个图片代表的意思,也可以让一些阅读器能够读出图片代表的意思。
技术性优化
SEO的优化是针对爬虫的,而爬虫本质是个程序,程序总会出问题。要想让爬虫能正常持续的爬取网站内容并建立索引最终让你的页面能出现到搜索结果页前面,那网站的技术方面一定要达标才行,而技术性优化主要是针对这方面来作用的。
加载速度
网站的加载速度至关重要,这体现在以下几个方面:
如果你的页面在3秒内还没有加载出来,用户可能会焦虑而直接离开。网站加载速度越慢,爬虫爬取的频率也会越慢。曾经我在一个流量站测试过,当网站在100ms内响应完毕和网站在几秒响应, 爬虫爬取量直接折半了。Google对新站一天之内只爬取半小时,由于爬虫时间的限制,如果你网站响应速度太慢,那一天爬取的量也很有限,如果你的网页达数十万之多,那会影响页面爬取覆盖率。怎么测试网站的加载速度呢?可以使用Google的PageSpeed Insights:
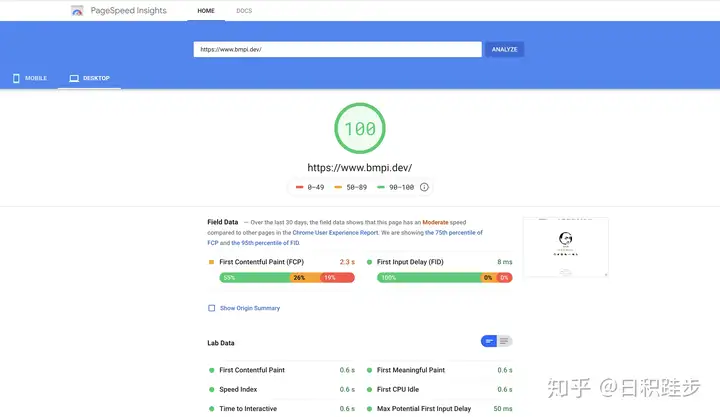
如上图所示,Google这个工具会给你的网站在加载速度方面进行评分,同时会给你如何提高加载速度进行分析指导。尤其注意移动端的加载速度,因为Google现在的移动端搜索流量已经超过了PC的流量了,所以Google对它的PageRank算法进行了更新,移动端对网站的总体评分影响更大。
移动适配
先看下面这两个统计信息:
Google搜索的63%来自移动设备,并且这一数字每年都在增长。280%的用户遇到再他们设备显示不好的内容时会停止使用3。可以对网站的移动端适配做一个检测,使用Google提供的Mobile-Friendly Test:
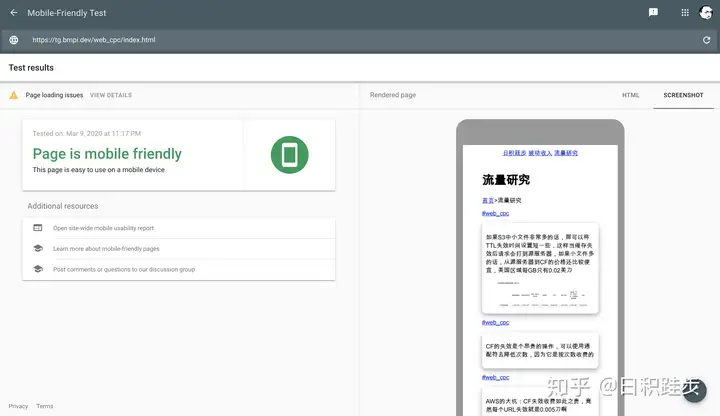
重复内容检测
网站的重复内容过多,会让Google认为该站的质量很低,从而降低网站的评分(权威度)。

之前我做了一个工具来分析一个网站的内容相似度,具体可以查看这篇《使用TF-IDF算法计算网站页面相似度分布(Python)》。
Canonical

如上图,该标签属于网页Head信息,给爬虫标记该页面唯一的URL。
404
当页面出现大量404的时候,Google会降低爬虫爬取频率,甚至会介入人工审查判定此网站是否为垃圾网站。一般静态化的网站无此问题(静态化网站模版里的链接错误可引发大量404),动态化的接口或者服务端渲染网站因数据库或服务器的错误可能引发大量404页面的响应。所以我们需要对服务器的日志做监控报警来及时发现此类问题并修复。

总之,不要让网站出现大量404页面。如果因为服务器的性能问题,可通过返回429来表明网站超负荷,爬虫看到此响应也会主动降低爬取频率。
重定向
当你想对网站的链接做重构,或者调整一些链接的时候,一定不要直接删掉之前的链接,而是通过保留之前链接并通过301跳转至新的位置。
301表明网页永久的移动到新位置了。这样做可以传递网页的权重。302表明网页临时移动到新位置。这样爬虫也会保留老的页面索引。sitemap.xml
sitemap相当于站点地图,当然一般网站也会有html版本的站点地图。当你有大量的页面而页面直接的链接不是很完整(可能会出现孤岛页面),最好有个sitemap.xml文件帮助爬虫高效的找到所有可索引的页面。

目前sitemap有很多工具化的插件可以生成,也可以自己开发,本质就是一个xml文件。
robots.txt
搜索引擎的友好类型的爬虫在爬取一个网站时,第一步肯定是查看robots.txt,这是一份协议,你可以用它来表明自己的站允许哪些类型的爬虫来爬取哪些类型的页面路径。你肯定在想为什么需要这么做?
有些动态类型网站有管理页面及一些没必要索引的页面,需要通过robots.txt来屏蔽爬虫索引。你的网站有CDN,而CDN的流量是很贵的。如果你的网站只面向Google的话,那就没必要让Bing/Yahoo/Yandex/Baidu的爬虫来耗费你宝贵的CDN流量。实际上我一个流量站里每天爬虫高峰时期发出50多万的请求,服务器每天30GB的出口带宽流量,如果控制不好爬虫,你的服务器很大部分的资源都是在给爬虫服务的。这还不说有各种恶意爬虫来爬取你的资源。还有一些爬虫是做各种数据分析的,比如SEO的一些工具网站semrush/ahrefs的爬虫。如下是我曾做过的一个站点的robots.txt:
如上这个robots.txt屏蔽了大部分知名的爬虫,只允许Google的爬虫以特定的频率来爬取网站。当然这只是一个友好的声明,它无法阻止恶意的爬虫,如果你的网站很多资源都是自己创作或整理的,又担心别人很随意的爬取了,那就可以使用一些反爬虫的CDN。
爬虫与反爬虫
有矛就有盾。我们可以很简单的开发出各类网站的爬虫,甚至有专门的Sass服务来帮你爬取特定站点。事实上互联网上的绝大部分流量都是爬虫类型的。我们先开始讲讲爬虫的爬取原理。
如何爬取一个网站?
以Python知名的爬虫框架scrapy为例,你可以很容易用它来写一个scrape的刮取器。在这里我们先搞清楚,虽然中文都是叫爬虫,但实际上英文里分为crawler和scrape,前者是全站类型的爬虫,比如搜索引擎用的就是这种,Java里开源的nutch就是一种全站的爬虫,它可以像搜索引擎一样递归的爬取整个互联网关联的所有网站。我们个人或者绝大部分公司用的都不是这种crawler,而是scrape。scrape是刮取的意思,就是通过xpath之类的技术将网页特定的数据抽取出来存入数据库供分析和进一步使用。scrape里又分为screen scrape和api scrape。前者就是将网页里的Html元素里的数据抽取出来,后者是直接破解网站的接口来调取结构化的数据。这两者难度都依据你要爬取网站的不同而不同,当然也可以结合使用。screen scrape更适合静态化的Html网站,而api scrape更适合动态的接口网站。比如你要爬取vue/react这类重度Javascript化的网站,一般可以先考虑破解接口,如果接口不好搞定可以使用一些渲染JS的服务,比如splash。当然写爬虫本身不是很难的事情,关键在于很多网站都有反爬虫的措施,最常见的就是限流,要破解限流就会牵扯出很多复杂的问题,比如你可能需要一些代理IP池,这些也都有成熟的商业服务可以购买。要破解网站验证码,也都有商业的打码网站帮你人工破解。如果你只想简单的去爬取网站,不想解决这类复杂的问题,可以直接使用商业的Sass服务比如scrapy作者的公司scrapinghub提供的服务。
如何反爬虫?
也有很多办法,最简单的当然是先用robots.txt屏蔽知名爬虫。然后在网站的接入层部署爬虫检测服务,只允许知名的爬虫爬取,一般知名的爬虫都提供验证机制,比如如果你从请求的UA里查看到Google的爬虫了,如果你要验证这个爬虫可以查看它的来源IP地址是不是Google真实的IP即可。对于伪装成用户的爬虫,你可以限制它的请求频率,比如做一个限流器来判定某个IP在某个时间窗口的请求数量是否超出你设置的限制。当然如果用户使用了代理IP池这种方法就很难反爬了。只能祭出大杀器:反爬虫CDN服务。我知道一个比较好的反爬CDN是Distil Networks,不过已经被imperva收购了。之所以推荐,是因为曾经尝试爬取过某个挂这个反爬CDN的网站,耗费很长时间都没能搞定。
索引状态
爬虫爬取你的网站页面后,这些页面就进入了索引状态,被索引的页面经过排名后才能展示到用户的搜索结果页里,所以观察索引状态很重要。怎么查看网站的索引状态?
在浏览器无痕模式访问Google使用site命令:

Search Console可以帮助我们发现网站的索引问题,如上图红色的Error、Valid和Excluded都是重点关注的点,在底部又可以点击进去查看具体的问题。
可用性
使用Chrome提供的网页Audits里有个Accessibility,如下图:

它会提醒你当前网页在这个维度有哪些待优化的点。
结构化数据

这种适合购物或者评测网站,具体怎么添加可以Google查询下,这里不在赘述。
站外优化
在Google的算法中,站外的反向链接更像是一种投票,如果你的反向链接很多(就是别人的网站里有你的网页链接),准确的说应该是高质量的反向链接很多(高质量意味着链接你的网站总体评分很高,也就是权威度高),那Google就认为这个被链接的站是个优秀的网站,你的网站评分就会高起来。
如何获取外链
最好的外链获取方式,其实就是内容。
友情链接
这可能是小网站或者博客最早最常见的获取外链的方式了,但是这种一般由于和你链接的网站本身就是一个小透明,那效果也很一般,但是也算是一种免费的办法吧。
友情链接,先友后链吧。
社区推广
如果你的内容或者服务质量真的很好,那么你可以尝试在社区推广,当如注意不要频繁的发一些没有价值的信息,既浪费你的时间,对别人也是一种骚扰。一般来说,如果内容质量高,都可能会得到社区的大力推广,这样的话效果还是很不错的。
比如我的这篇《年轻上班族的系统化投资之路》在知乎获得了8万多的阅读,2700多的赞同和收藏:

而这篇《我的财务管理方案》在V2EX上获得了六千次的点击:

以上的推广带来了一部分引荐流量:

当然你会发现社区的推广(也包括下边的社交网站)的流量特征是脉冲式的,随着时间的推移,逐渐衰减,而SEO的流量特征是持续增长的,如下图:

这也是我们为什么要做SEO的原因吧。
社交网站
数据显示1.3%的文章占据了社交分享的50%,所谓的爆款10万加的热门文章(第一周上万阅读、数百评论、数千分享、搜索引擎关键词排名第一),爆款文章写作耗时长,可能得数十小时的投入。
不要直接在社交媒体发布博客文章链接,现在的社交媒体算法更喜欢在社交媒体的原生内容,所以直接在社交媒体/社区帖子中写一些原创的或者文章里有的一些有意思的观点/数据,然后在帖子中将文章链接植入进去,完成引流。
掏钱买
用钱是最快的一种方式,直接掏钱/赞助某个你觉得不错的网站,这属于付费推广(广告)的一种了。当然效果一般来说不是那么好,但是速度飞快。不过如果你外链突然暴增,Google也会发现异常,可能会被惩罚。
如何查询反向链接
免费的方式可以通过Google Search Console和semrush:


收费的方式可通过ahrefs:

监控追踪
通过对流量的监控与追踪,我们可以发现网站的整体状态,比如跳出率过高意味着我们网站的整体价值比较低,需要提高网站的内容质量;通过找出热门的页面,给冷门页面传递权重;每年定期将流量低的文章重新更新发布来提高单个页面的流量价值。
如何监控追踪?
Google Analytics





Google Search Console

资源工具
资源
教程
必看的肯定是Google网站指南了。
赚钱的方法都写在刑法里了,获取流量的方法都写在Google网站质量指南里了:

如上都是一些曾经的SEO黑科技,当然目前是否有效还不确定。不过要想长期做站,这些方法都不可取,但是在曾经,它们都是暴力快速获取流量的方法。
文章推荐
什么是SEO?如何针对Google这样的搜索引擎进行优化How to Learn SEO (and Stay Sane)提升网站排名的公开“秘密”谈谈我理解的流量Is SEO Dead? (A Data-Driven Answer)Youtube Channel
AhrefsBrian DeanNeil PatelTwitter List
SEO List工具
Google Site Command:查看收录索引状态Google Search Console:站长工具,查看页面爬取状态等Google Analytics:流量监控及数据分析Chrome Audits:是个不错的站点审计工具(访问速度、可用性、最佳实践、SEO、PWA)ahrefs:反向链接分析semrush:流量分析SEO需要注意的问题
Google沙盒期
虽然Google不承认新网站存在一段沙盒期,但是从实际操作来看,新站容易进入沙盒期。进入沙盒器的网站,几乎没有什么SEO的流量。这时候不要焦虑,正常更新内容做好SEO即可。你可以把沙盒期理解为Google的考核。一般一个月即可渡过,但是也有数月流量才正常的。
域名黑历史
买域名前一定要查查这个域名是否干净,否则对SEO的影响可能是致命的。一般可通过上述一些查询反向链接的方法,也可以通过Wayback Machine去查询网站的缓存历史。
SEO的周期
SEO一般都是很慢的,流量的变化周期都以月计数,出现一个问题修复测试都是按周计。如果想短期流量暴增,那SEO肯定干不了这个。如果想通过一些黑科技去控制Google来提高流量,短期来说也是可能的,但是长期避免不了被Kill站,如果想长期做,还是一步一步来吧。
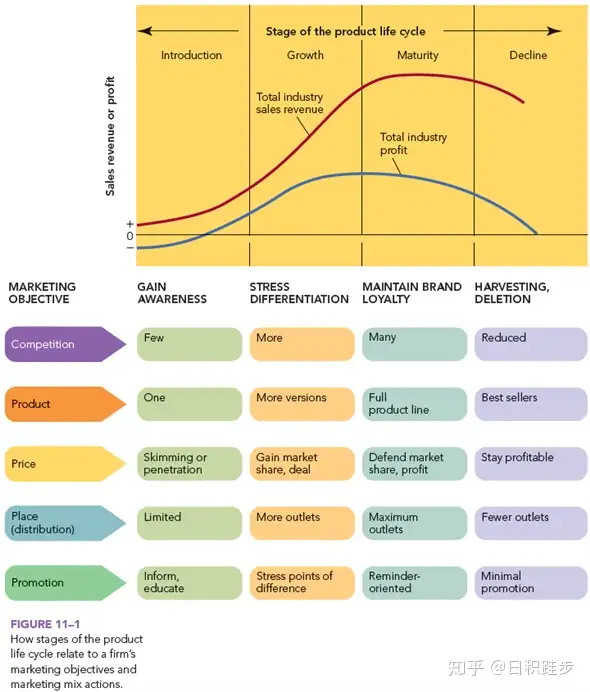
SEO 未来
都2020年了,SEO有未来吗?
或许每个人都有自己的答案,我曾在V2EX上发了一个帖子:《SEO的未来在哪里?》。经过这个帖子的讨论,我逐渐认识到之前一些SEOer的经验早已经没有用了,很多人拿着旧有的经验来判断未来,殊不知变化来的太快。
我坚信SEO还是有效的,它更是一种对网站内容方面和技术方面架构的方法论,这个方法论帮助我们做出对受众更好的内容。
SEO IS NOT DEAD, IT’S JUST CHANGING
References
https://www.seoactionblog.com/will-seo-die/ ↩︎https://www.statista.com/statistics/275814/mobile-share-of-organic-search-engine-visits/ ↩︎https://www.sweor.com/firstimpressions ↩︎免责声明:本站所有内容及图片均采集来源于网络,并无商业使用,如若侵权请联系删除。
上一篇:SEO 是什么?
